这两天帮楠妹做了一点事情,涉及从PDF中提取表格,使用了两个开源工具 PDFMiner 和 PyPDF2,记录一下提取过程。
具体是需要从一个网站上下载 28000+ 个PDF,每个PDF大概150页,每个PDF只提取一个表格的信息。
下载PDF这个事情用 爬虫 就可以搞定了,但是提取PDF就比较麻烦了。并没有直接的工具可以将PDF中的表格导出,所以只能用最笨的方法,提取文字再恢复成表格。
根据自带outline提取页码
提取文字需要定位文字,不然150多页的PDF遍历起来也是很费劲。但是 PDFMiner 支持提取提纲,但提纲对应的destination没什么卵用。
Some PDF documents use page numbers as destinations, while others use page numbers and the physical location within the page. Since PDF does not have a logical structure, and it does not provide a way to refer to any in-page object from the outside, there’s no way to tell exactly which part of text these destinations are referring to.
于是搜索了一下其他方法,找到了StackOverflow上一个 回答,这里我直接把代码贴上来了。
1 | #从outline获取页码 返回列表 |
这段代码会返回一个页码列表,是深度优先的顺序,然后根据想要的位置找到列表的页码索引便可以得到页码了。
提取表格
根据正文提取内容并不是直接抓就可以了,PDF的生成渲染机制(暂且这么称呼)很奇怪,表格行列出现的顺序甚至会出现完全随机的情况,所以基本用规律或者正则表达式页很难提取。
PDF is evil. Although it is called a PDF “document”, it’s nothing like Word or HTML document. PDF is more like a graphic representation. PDF contents are just a bunch of instructions that tell how to place the stuff at each exact position on a display or paper. In most cases, it has no logical structure such as sentences or paragraphs and it cannot adapt itself when the paper size changes. PDFMiner attempts to reconstruct some of those structures by guessing from its positioning, but there’s nothing guaranteed to work. Ugly, I know. Again, PDF is evil.

还好天无绝人之路,这篇 博客 启发了我。 其实原理就是每个pdf里的一段文字都是一个对象,对象通过坐标标示位置,然后附带内容。每一个PDF页都是一个平面,其中左下角是0,x轴向右延伸,y轴向上延伸。先通过某些文字的内容确定表格的坐标,这里要根据自己的内容选取,例如我的表格是这样的:
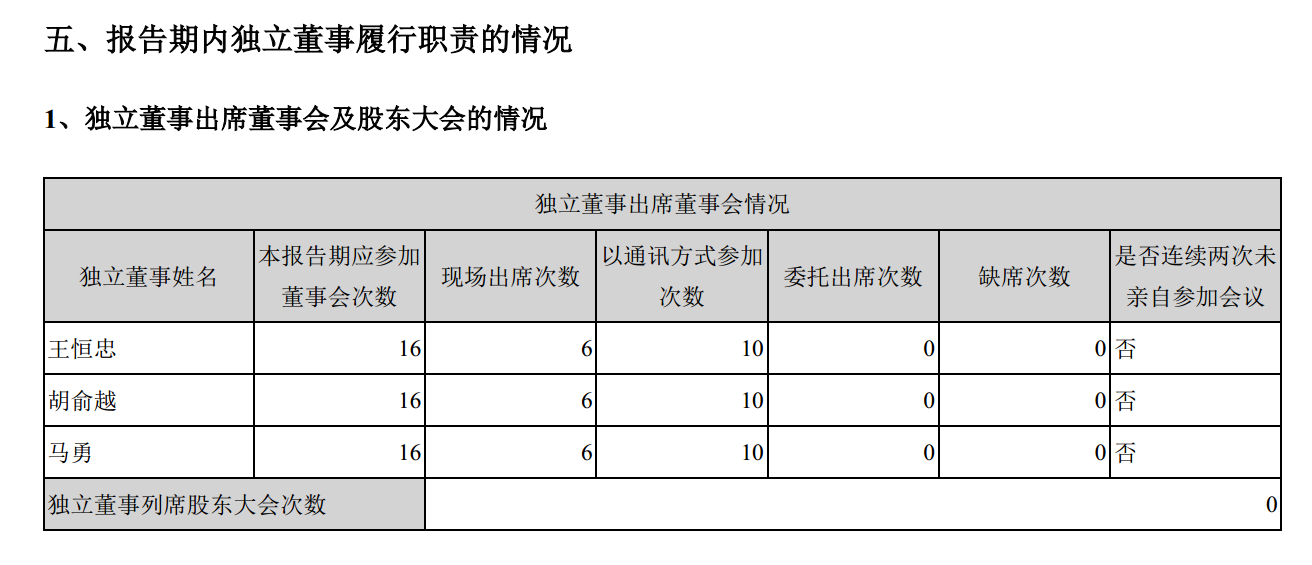
我选取了8个x值,4个y值。然后将内容按照y值降序排列,根据x的值每一列地选取。
1 | #x0 x1 x2 x3 x4 x5 x6 x7 |
方法很蠢,仅供参考:
1 | def pdfHandler(filetitle): |
反正最终我维护了地球和平…