GlusterFS 是一个开源的网络分布式文件系统,前一阵子看了一点GlusterFS(Gluster)的代码,修改了部分代码,具体是增加了一个定制的xlator,简单记录一下。
Gluster与xlator
随着计算机技术的发展,不管哪一个领域的数据都呈现出爆炸性增长的趋势,因此产生了大数据处理与存储技术。单机的存储基本不可能满足大量离线数据(文本)的存储需求了,于是在网络分布式文件系统越来越受到重视。开源的分布式文件系统非常多,GlusterFS,Lustre,Ceph,HDFS,FastDFS,关于这些文件系统的分类与区别,可以参考这里,我觉得从块,文件,对象的角度划分比较靠谱。我本是做高性能计算的存储方面研究的,阴差阳错地入了Gluster的坑,具体原因不表了。
Gluster是基于FUSE的用户态文件系统,意味着编译安装Gluster不需要去牵涉内核,关于FUSE,其实Gluster做的比较粗暴,用一个死循环去读取/dev/fuse这个块设备,再丢给客户端或者网络,但是FUSE的原理还是值得去研究的,我也是一知半解。兼容POSIX标准,意味着Linux标准库的read,write等I/O函数不需要经过修改就可以在Gluster上运行。
一个网络分布式文件系统的套路通常是,服务端有多台机子构成一个统一的名字空间,文件以某种分布方式存放在不同的服务器上。而客户端看到的却是一个整体,如一个目录,并且客户端可以被挂载在多个不同的节点,因此可以随时随地访问你的数据。每个文件系统为了实现这一套,都会有各种各样的概念,但本质都是一样的,例如Gluster里面有一些基础的概念, 其中brick是一个存储节点上的一个输出目录, volume是一系列的brick,代表一个功能子集,translator(xlator)是连接子volume的,xlator本身也是某一个volume的具体实现。
Gluster支持多种数据分布方式:
Distributed(默认分布方式)
一个文件分布在一个brick上,不同的文件可能分布在不同的brick上。没有容错。Distributed方式的分配粒度是文件。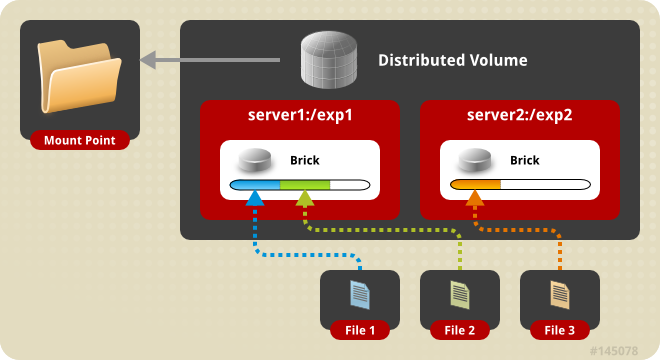
Replicated
每一个文件都会在每个brick存一个copy,replica数目可以由配置文件指定。Replicated的分配粒度是文件。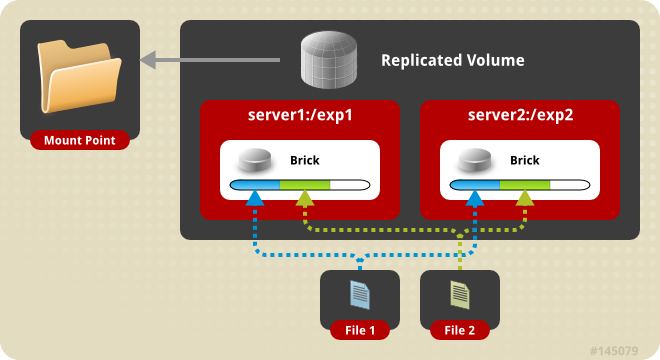
Distributed Replicated volume
前两者的结合,brick的数量是replia的n倍,假如有N个brick,replica是2,则distribute数目是N/2,相邻的两个brick互为备份。先distribute,再replicate。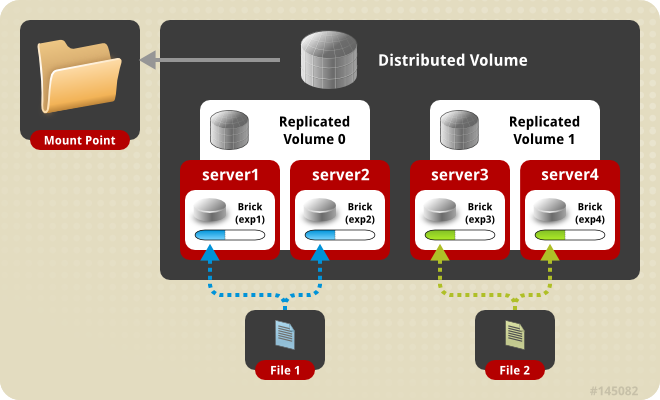
Striped Volume
文件被分成固定大小的块,以RR方式分布在不同的服务器上。Striped的分配粒度是文件块。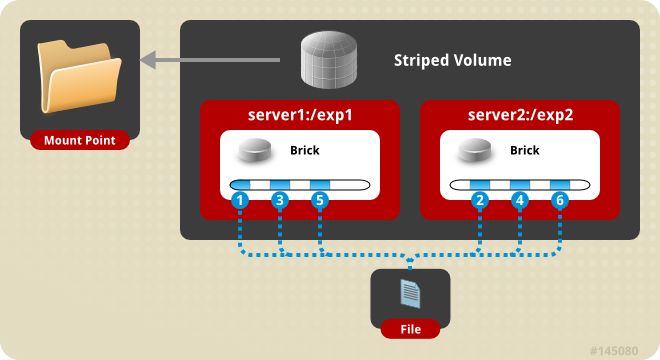
Distributed Striped volume
与striped 方式不同的是,file只在特定的brick上面stripe,相当于先distribute,再stripe。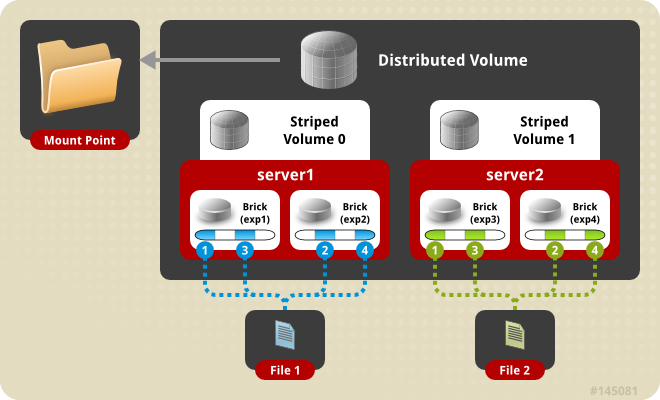
xlator是Gluster设计的精髓所在,每一个功能都可以用一个xlator来实现,例如每种分布规则对应一个xlator,另外一些feature可以封装在一个xlator中,如文件加密。并且可以在配置文件中各种xlator混合,嵌套使用,每个xlator编译后会生成一个动态链接库,运行时按需加载。
举一个例子,上面五种分布方式的第五种 Distributed Striped Volume,他的配置文件这样写:
1 | ************************************************************* |
配置文件是一种树形的xlator结构,树的根是fuse_xlator_t,在配置文件初始化的时候,由根向叶子深度优先初始化。写配置文件的顺序与Gluster读配置的顺序是相反的,例如:dht最先被读取。client端的配置文件的写法要比server端复杂,server端只需要指定哪个目录输出就足够了。
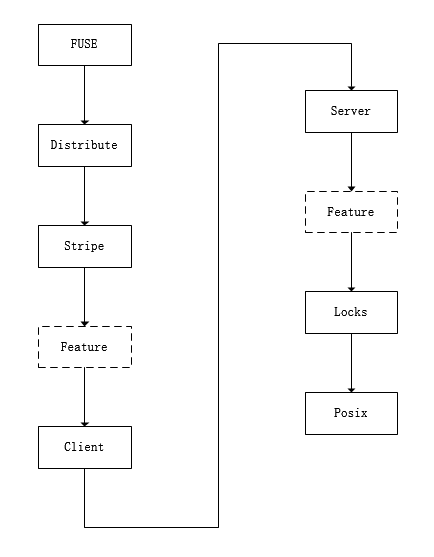
如图所示,左边是客户端的xlator嵌套关系,fuse初始化之后会初始化子卷 subvolume,即调用dht的初始化函数,依次完成初始化。同样,一个I/O请求被FUSE接受,会经过一些封装传递给dht,dht可能经过一些定位,传递给他的某一个subvolume,…一直请求由client xlator通过网络包发给对应的server。server端收到请求也同样是一样的嵌套处理,最终会把请求送到posix xlator,这个xlator里封装了最原始的系统调用,read,write等。这就是Gluster整个系统的执行流程。

上图是官方文档提供的所有类型的xlator,具体都可以在源代码xlators/目录里找到。
xlator中的调用(STACK_WIND)与回调(STACK_UNWIND)
Gluster在不同层级的xlator之间的通信有点类似于递归,主要依赖于代码中的两个宏,分别是STACK_WIND和STACK_UNWIND。每一个xlator中的相关函数都有一对,如 write 函数有着对应的 write_cbk 函数,两个函数与两个宏定义配合使用。

我们把xlator的关系简化成三层,FUSE,DHT,POSIX,关系如上图左边所示。假设系统从/dev/fuse中读到了一个write请求,系统将这个请求丢给FUSE xlator,在FUSE xlator中调用fuse_write,通过STACK_WIND将请求传递给他的subvolume,调用subvolume对应的write函数,即dht_write, dht_write同理通过STACK_WIND调用posix_write。在图中posix是最底层的xlator,因此posix_write将不会调用STACK_WIND,而是调用STACK_UNWIND将返回值或者结果返回给父volume,对应着调用父volume中的_cbk函数,即dht_write_cbk,该函数做完相应的处理后继续通过STACK_UNWIND返回到fuse_write_cbk中,这样一个write才算完成。
调用 (STACK_WIND)
接着具体分析一下STACK_WIND是如何工作的。下面是STACK\_WIND的宏定义。
1 | /* make a call */ |
在dht xlator中,dht_write 函数里这样调用STACK_WIND:
1 | STACK_WIND (frame, dht_writev_cbk, |
把参数代入到宏定义中,可以按照下面的代码理解:
1 | new->parent = frame; |
可以看到STACK_WIND主要做了三件微小的事,1 传递调用之间的上下文,代码中是frame 这个数据结构,2 记录当前函数的回调函数,一般是对应的cbk函数,也有特例,像dht xlator中逻辑比较复杂的lookup操作(关于Gluster的核心dht xlator的调用分析可以参考这里),3 调用子subvolume的对应函数,将操作向下传递。
因此按照我们简化的xlator关系,即dht的subvolume是posix,那上面的STACK_WIND就调用了posix_writev:
1 | posix_writev (call_frame_t *frame, xlator_t *this, |
回调 (STACK_UNWIND)
接下来看一下STACK_UNWIND的工作原理。Gluster中有两种回调的宏,一个是STACK_UNWIND, 另一个是STACK_UNWIND_STRICT,两者的差别只是第一个参数,原理是一样的。通常xlator源码里面用的是STACK_UNWIND_STRICT,原因在宏定义的注释里写了,STACK_UNWIND_STRICT是类型安全的。下面是STACK_UNWIND_STRICT的宏定义。
1 | /* return from function in type-safe way */ |
前面提到如果你的xlator是最底层的(如客户端的client xlator,服务端的posix xlator),那么这个xlator里不应该存在 xxx_cbk 函数,而是在操作返回之前调用STACK_UNWIND或者STACK_UNWIND_STRICK。posix xlator里面用的是STACK_UNWIND_STRICT 向父volume返回。 STACK_UNWIND_STRICT的第一句是将第一个参数连接成cbk函数,以下是posix的调用:
1 | STACK_UNWIND_STRICT (writev, frame, op_ret, op_errno, &preop, &postop); |
把参数代入到宏定义中,可以按照下面的代码理解:
1 | //这里的frame就是STACK_WIND里的obj |
可以看到替换后,首先将上下文换成正确的上下文,即父volume的frame,然后代码的最后一句实际是调用了父volume的 cbk 方法,即dht_write_cbk,在dht_write_cbk里会继续调用STACK_UNWIND_STRICT, 这样就会将结果返回到根xlator。
工程编译,configure与make
为Gluster新增xlator实际是改变了源码的结构,因此要想xlator正确工作,需要了解一下自动编译的知识。首先看一下Gluster的代码结构:
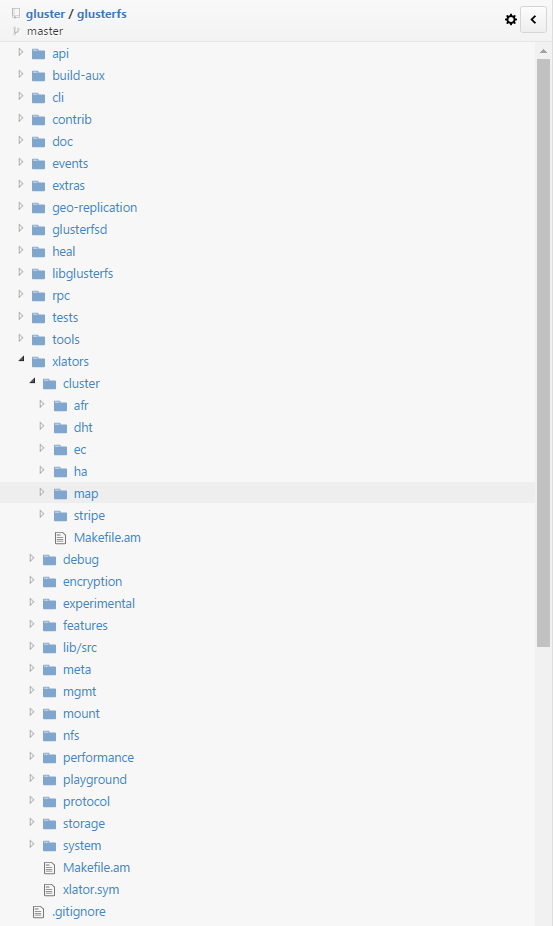
Gluster里提供了一个默认的xlator模板叫做defaults,在libglusterfs/src/defaults.c里,里面定义了一个文件系统基本操作,包括cbk方法,但是他不做任何操作,方法里面只有基本的STACK_WIND和STACK_UNWIND调用。假设我们要在cluster中加一个新的分布规则叫dadada,那应该在对应的目录下新建自己的目录和源码,如图:
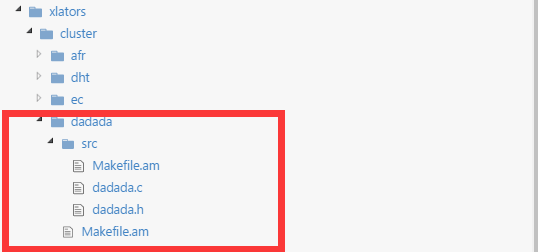
然后需要将新增的xlator加到编译选项中。为此我特意了解了一下C语言大型工程的编译套路,仅仅也是能够修改的水平。首先基础的编译方法是用make命令执行Makefile文件,GNU提供了一系列的工具帮助我们自动生成Makefile文件。下面是生成Makefile的操作过程(原图):

首先通过autoscan根据源代码生成对应的configure.ac(或者configure.in)文件,不过通常这一步不需要我们做,一般开源项目里都提供了configure.ac文件。然后aclocal命令根据configure.ac生成aclocal.m4,再运行autoconf命令生成configure文件,然后需要运行automake -a命令生成makefile.in,但这三个步骤Gluster里面有一个autogen.sh的脚本帮我们做了。生成的configure文件是可以执行的,必要的时候修改一下文件权限。执行configure文件,该文件会和makefile.in一起生成所需要的Makefile文件。
因此可以看到,在编译中通常我们只需要提供configure.ac(configure.in)和Makefile.am两种文件,其他都是通过工具自动生成的。所以我们要为我们的dadada做以下修改:
1 修改configure.ac, 将cluster/dadada 和 cluster/dadada/src 仿照其他的结构添加到configure.ac中。当然要修改的不只下图中的一处。
2 修改Makefile.am,包括cluster/Makefile.am,cluster/dadada/Makefile.am, cluster/dadada/src/Makefile.am,基本就是改一些名字。
1 | # cluster/Makefile.am |
3 运行autogen.sh,该脚本是用aclocal和autoconf生成configure文件,以及用automake生成Makefile.in
4 运行configure, configure是用Makefile.in 生成Makefile
5 make && make install
配置文件以及其他
在完成编译之后便可以自己写配置文件进行测试了,一个示例的配置文件:
1 | ## client 1 |
以上就是关于增加xlator所能想起来的基础知识,当然写一个xlator是非常困难的,需要理解和研究的东西的太多。有一个建议就是涉及逻辑的操作最好在cbk函数里面做处理,嵌套调用写在 STACK_UNWIND 前面。另外Gluster在高性能领域用的比较少,所有的文件系统都是有利有弊的,例如Gluster的一大特色就是没有集中的元数据服务器,文件的定位是根据文件名计算hash值来做的,因此Gluster没有分布式文件系统中常见的元数据瓶颈问题,但是在没有指定文件名时候做查询(ls),Gluster性能就不会很好,因为要全盘扫描,关于Gluster性能的探讨,推荐这个系列的博客。关于Gluster开发过程的调试方法,可以参考这里。
以上。
参考
https://www.gluster.org/
http://lustre.org/
http://ceph.com/
https://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.html
https://github.com/happyfish100/fastdfs
https://turodj.gitbooks.io/those-things-about-architecture/content/cun_chu.html
http://gluster.readthedocs.org/en/latest/Administrator%20Guide/glossary/
http://lidawn.github.io/2015/04/30/parallel-io-basic/
http://blog.csdn.net/liuhong1123/article/details/8118258
https://www.ibm.com/developerworks/cn/linux/l-makefile/
http://blog.csdn.net/liuaigui/article/details/6284551
http://pl.atyp.us/hekafs.org/index.php/2011/11/