一个二叉排序树的例子
首先看一个常见的二叉排序树的操作,下面的代码包括插入、创建和中序遍历。摘自这里。
1 |
|
我一直很纳闷为什么插入(创建)操作需要传递指针的指针,不是指针就可以操作被指向的内容吗?为解决这个疑惑,首先看一下C语言的函数传参。
C语言函数传参
一个经典的例子就是交换两个数的值,swap(int a,int b),大家都知道这样做a和b的值不会被交换,需要swap(int *a,int *b)。从函数调用的形式看,传参分为传值和传指针两种(C++中还有传引用)。实际上在C语言中,值传递是唯一可用的参数传递机制,函数参数压栈的是参数的副本。传指针时压栈的是指针变量的副本,但当你对指针解指针操作时,其值是指向原来的那个变量,所以可以对原来变量操作。
分析
再看一下前面的二叉树插入的例子。
1 | BTreeNode *root=NULL; // STEP 1 |
函数递归调用,每次真正产生变化的时候传递进去的都是空指针。当树根为空时,我们图解看一下函数调用的值拷贝。
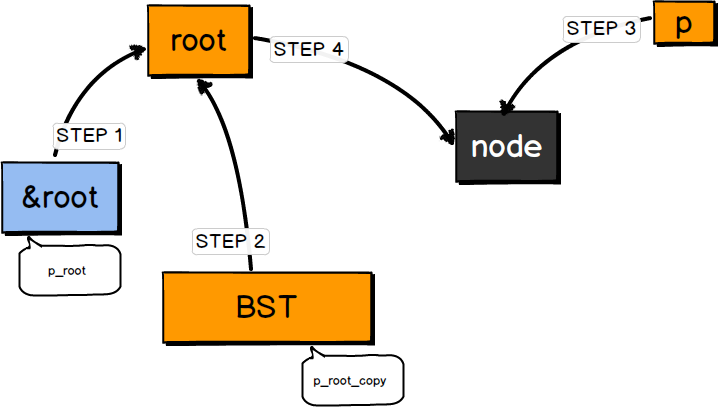
STEP 1 定义一个空指针root,&root为指针root的地址,图中的箭头表示指针的指向。
STEP 2 调用Insert,产生一个&root的拷贝BST,即BST指向root。
STEP 3 生成一个新的节点为node,由指针p指向node。
STEP 4 (*BST)=p,也就是root的值为p(node的地址),于是root指向了新生成的节点。
如果我们把函数与调用改成一级指针,看下面的代码:
1 | BTreeNode *root=NULL; // STEP 1 |
再图解一下调用过程。
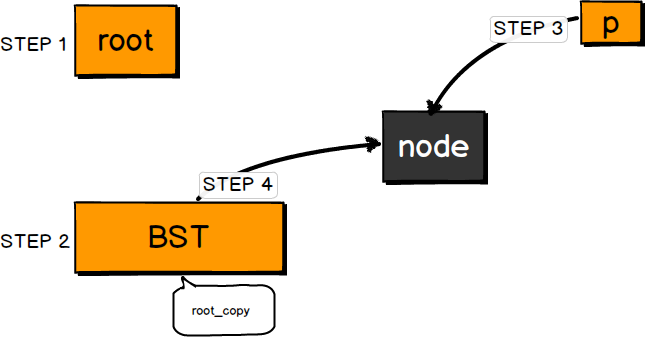
STEP 1 定义一个空指针root。
STEP 2 调用Insert,产生一个root的拷贝BST,BST与root的值一样都为空,所以都没有指向。
STEP 3 生成一个新的节点为node,由指针p指向node。
STEP 4 BST=p,也就是BST的值为p(node的地址),于是BST指向了新生成的节点。
执行结束后我们得到了一个根节点但是root并没有指向这个节点。
那么能不能通过一级的指针就得到正确结果呢?答案是可以,看两个图的区别,其实就是root最后要指向node,即root=BST。所以只需要给函数加一个返回值,就可以通过一级指针得到同样的结果,看下面的代码:
1 | //调用 |
结果正确:
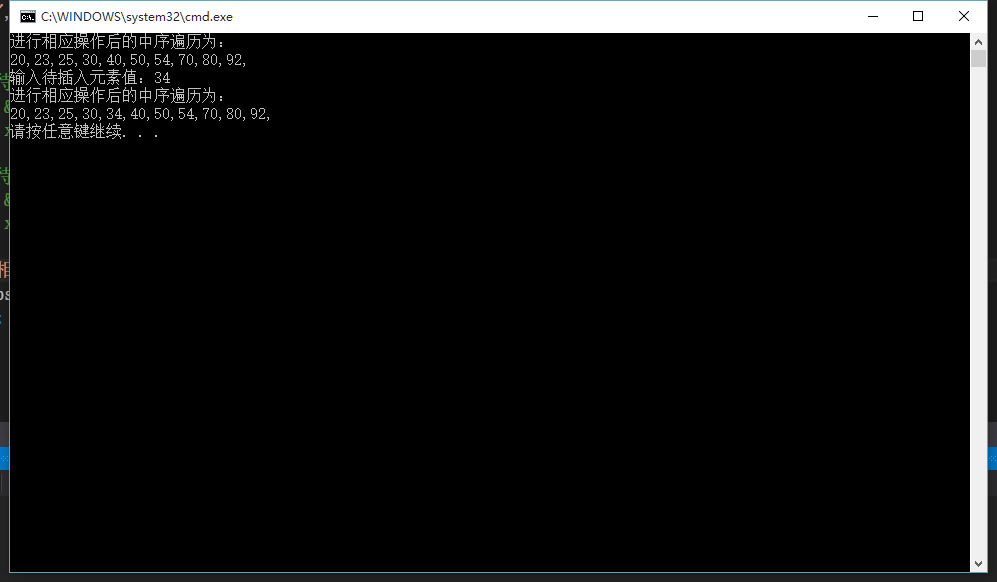
但是从语义上看,一级指针的写法没有二级指针那么直观,遇到需要对树进行修改的操作时还是用二级指针更好一点。