前几天涵哥找人帮她写一个图片爬虫,碰巧我以前曾经有过一点点爬虫经验,于是用python写了一个非常简单的百度图片爬虫。
1.分析图片地址
最简单的爬虫就是分析网页的HTML代码,从代码中的<a>或者<img>标签中找图片地址,然后用urllib或者request库函数下载,所以我也是这样做的。
首先在chrome中打开百度图片搜索的结果页面,然后审查元素,然后找图片标签,结果是这样的:
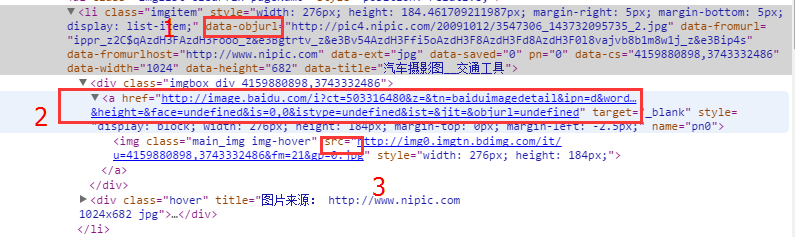
这里有几个值得注意的地方:
- 图片是以无序列表
<ul>呈现的,每个图为一个<li>子项,搭配各种css。 data-objurl(对应图中1)是图片的真实地址。<a>(对应图中2)是点击图片后的页面地址。src(对应图中3)是页面展示出来的小图地址。
其中data-objurl是我想要的地址。
所以大致思路出来了,先在搜索结果页面中遍历所有同类型的<li>标签,然后在其中找data-objurl,得到图片真实地址,匹配方法可以用BeautifulSoup或者正则表达式。
于是我先下载了一个搜索页面,测试匹配和如何遍历所有图片的真实地址,这里有经验的伙伴肯定就已经猜到了会出问题。没错,问题出现了,在我用如下代码下载的搜索页面HTML代码中,完全找不到所谓的<li>标签,跟别提data-objurl了。
1 | #coding:utf-8 |

这里问题的元凶就是AJAX了,通常这种有规律的列表类数据都会通过JavaScript异步请求服务器获得,服务器通常返回嵌入的HTML代码或者XML代码或者JSON代码,这样的设计能够让结果多次返回,有利于加强用户体验。
前面的方法虽然不能够得到结果了,但是也并不是没有收获,我们知道了在搜索结果页面加载后,图片的真实地址一定会返回到前端浏览器,只是返回的地址和格式不清楚罢了。
2.分析网络请求
打开chrome审查元素的network标签,重新加载搜索页面或者在页面下拉,可以看到浏览器收到了N多请求:
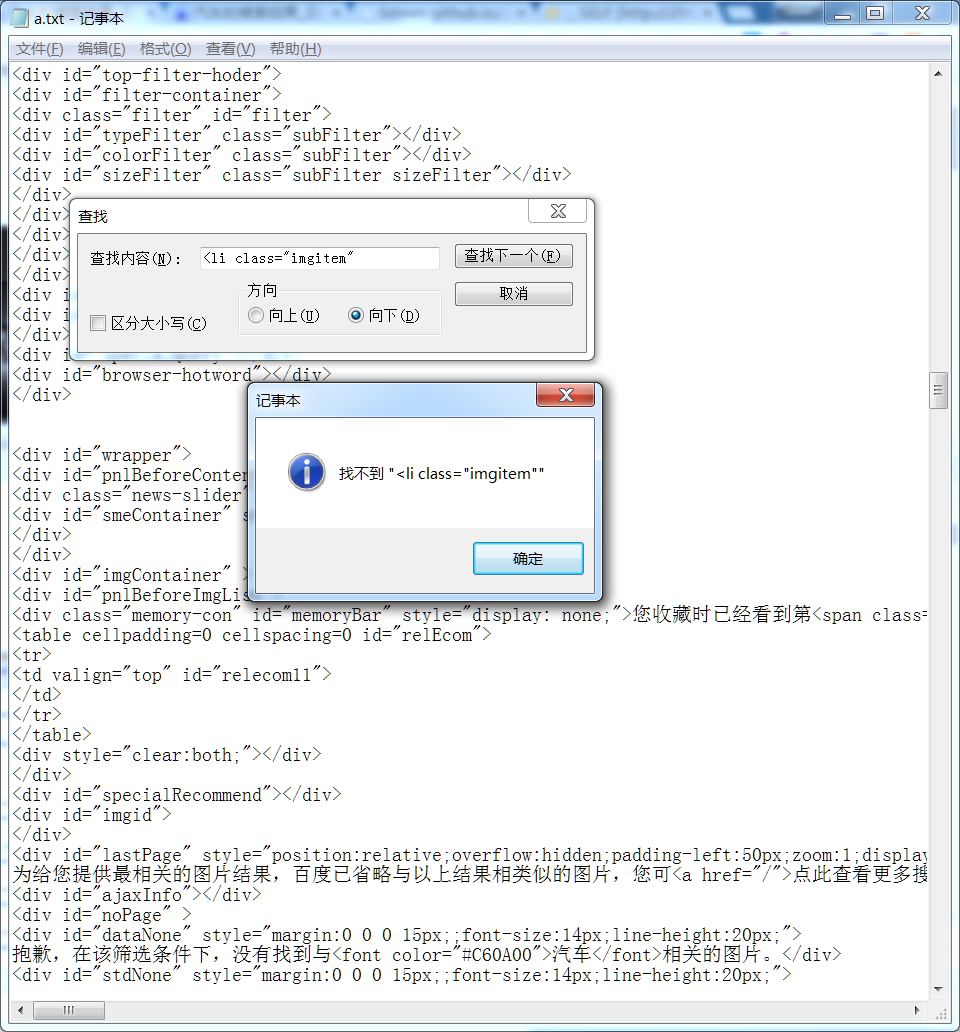
经过过滤,得到了JSON数据的链接:
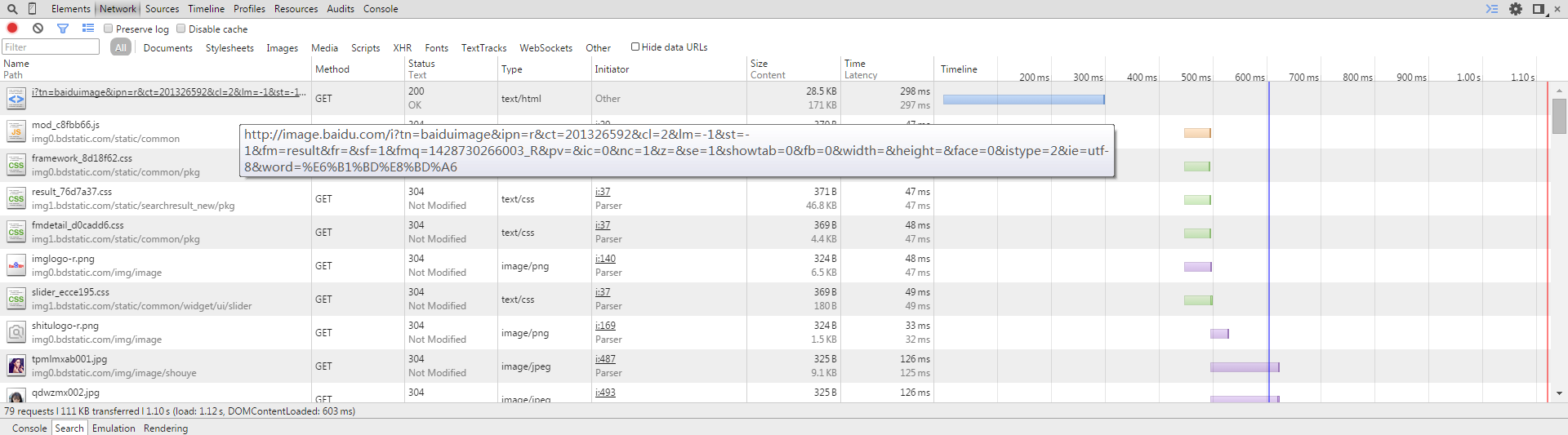
打开之后是这样的:
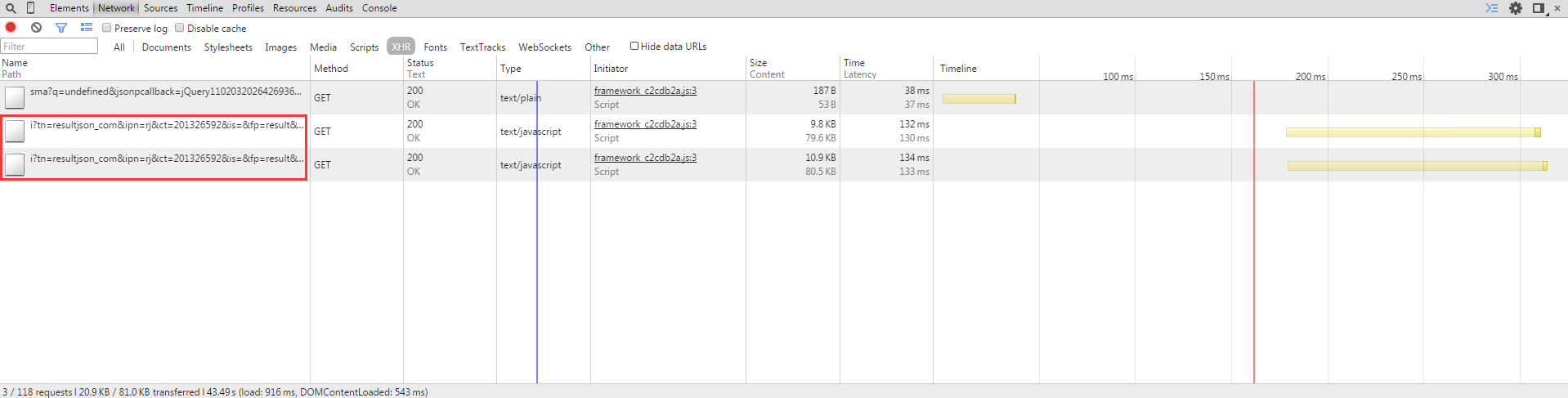
观察和调试URL参数,我们发现了三个有价值的参数,tn,rn,word,分别代表起始图片序号,返回图片数量以及关键字,改变这三个参数我们就可以得到任意想要的图片结果。
再看返回的JSON数据,objURL代表的是原始地址,就是我们想要的结果,可以用python的JSON库函数或者正则表达式将其读出。

但是细心的伙伴们又发现问题了,这个真实地址竟然是密文!!!
3.解密真实URL
百度也真是让人不省心,竟然给我们一堆密文。但是细一想明明图1中的data-objurl是明文,所以说解密的方法一定就在前端代码里了。咨询了组里的前端大神后,这个问题得到了完美解决(各种js设置断点,各种调试,找到了解密方法)。
原来的密文是这样的:
1 | ippr_z2C$qAzdH3FAzdH3Ft42d_z&e3B4pt4j_z&e3BvgAzdH3F7rAzdH3F8dabAzdH3Fdn88dabAzdH3FcdmDl88c-DBdb-9Aal-laCd-nnnFB889mCdE_caa_z&e3B3r2 |
解密后是这样的:
1 | http://img2.mtime.cn/up/1208/2311208/526D9115-DB28-4A09-90C2-333FB1146C2E_500.jpg |
其实就是一个简单的映射,映射方法是:
1 | "0": "7", "1": "d", "2": "g", "3": "j", "4": "m", "5": "o", "6": "r", "7": "u", "8": "1", |
额,百度真是用心良苦啊!!!
这里还有一个小插曲,在我写这篇文章的时候百度前端的代码已经跟我当时写爬虫时不一样了,本来页面中是没有真实地址的,地址解析是在onclick事件之后,当时的代码是这样的
而现今这个代码已经消失了,而且图片真实地址出现在了前面提到的
data-objurl中,估计是为了提高用户体验,在页面加载的时候提前解密了,大百度果然是精益求精,吊爆了!
4. 爬虫
写了一堆基本原理,终于可以写爬虫了,这个部分是最简单也最没有技术含量的。直接上代码吧。
1 | #coding:utf-8 |
代码在python2.7下运行,没有任何依赖。
马丹,博客和代码一样丑陋!!
gist: https://gist.github.com/lidawn/7e7e00f04e33bd5f803d
另汽车之家外观爬虫gist: https://gist.github.com/lidawn/61982497121e10720fff