1. 并行I/O介绍
本文将对并行I/O,主要是MPI-IO做一个简要介绍。在HPC领域,CPU速度与磁盘速度的差异使得I/O成为一个巨大的瓶颈。I/O分为读和写,HPC中,读操作通常在应用程序的启动时执行,如读初始参数,读checkpoint等,而写操作通常贯穿整个应用程序执行过程。由于程序写操作的不规则性(与底层文件系统),导致写比读面临的挑战要更大。
2. 并行文件系统与文件视图
2.1 并行文件系统
图1呈现的是并行I/O的体系结构。我们将节点分为计算节点和存储节点两种,每一种的数量都不限,但通常计算节点数目要多于存储节点,两者之间用网络连接。所谓并行I/O就是来自计算节点的多个进程同时将数据从计算节点的内存转移到存储节点的磁盘上(或者反过来)的过程。
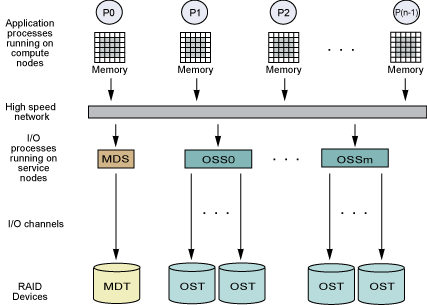
多个存储节点通常安装并行文件系统,将多个存储节点上的磁盘组织成为一个逻辑上统一的磁盘供计算节点使用,也就是说所有的进程只看到一个磁盘,但是这个磁盘的容量是所有存储节点的容量和。Lustre是目前最流行的并行文件系统,一种典型的Lustre部署是由一个元数据服务器(MDS)和多个对象存储服务器(OSS)组成。一个OSS又对应一个或者多个对象存储目标(OST),我们可以看做OSS是一个物理节点,OST是挂载在该物理节点上的磁盘,通常一个OSS对应一个OST。通过一个MDS和多个OSS的结构,Lustre可以将一个大文件拆分成多个部分并且分布到不同的OST上(RoundRobin方式:RR),从而达到并行读写的目的,而怎样分布这些数据记录在MDS中。应用程序读写文件时首先与MDS通讯获得文件分布的信息,然后直接与OST连接进行读写操作。
参考:RR
2.2 文件的物理视图和逻辑视图
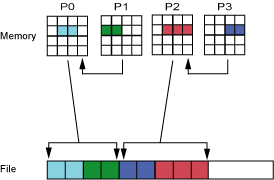
图2展示的是一个文件的物理视图,这个文件分为5块,分布在4个OST上(以RR方式)。
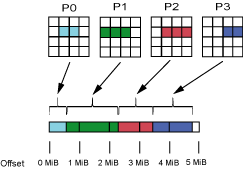
图3展示的是一个文件的逻辑视图,这个文件由连续的字节序列组成,逻辑视图是应用程序能看到的文件的样子,包括起始位置,长度等。
文件的逻辑视图与物理视图,即底层的文件系统,是没有关系的,但是了解逻辑视图与物理视图的对应关系对优化并行I/O性能有很大帮助。

Lustre将文件划分为N个块,并且以这个块作为最小操作单位。文件分片是Lustre的重要特性,涉及到两个参数stripe count和stripe size,stripe count是指对象数,即,将文件分布到几个OST上,也就是说stripe count小于等于OST的数目。Lustre可以支持几千个OST,但是stripe count最大为160。stripe size就是分片大小。Lustre默认的stripe count是1,stripe size是1MiB。
图4展示的是逻辑视图与物理视图的对应关系。
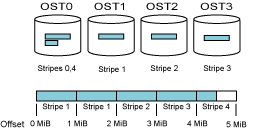
图5展示的是一个物理视图上简单的并行I/O。四个进程并行地写一个分布在四个OST上的文件,stripe size是1MiB,每个进程写一个连续的块。
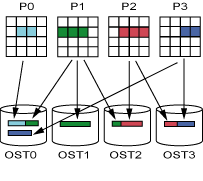
- P0写长度为600,000 byte的记录,起始offset为0,记录分布在OST0上
- P1写长度为1,800,000 byte的记录,起始offset为600,000,记录分布在OST0,OST1和OST2上
- P2写长度为1,200,000 byte的记录,起始offset为2,400,000,记录分布在OST2和OST3上
- P3写长度为1,400,000 byte的记录,起始offset为3,600,000,记录分布在OST3和OST0上
进程0-3写的记录被Lustre自动分布在不同的OST上,OST0同时接受来自P0、P1和P3的数据,OST2同时接收来自P1和P2的数据,OST3同时接收来自P2和P3的数据。四个OST同时接收数据,这样I/O速度理论上是一个OST接收速度的四倍。但实际上,I/O速度还被其他因素限制。首先是“对齐”限制,由于记录的长度不是stripe size的整数倍,导致offset没有与stripe的边界对齐。其次是“锁”限制,当多个进程同时写同一个OST的同一块数据时,Lustre会给该块数据加上“锁”限制,也就是这一块数据每次只允许一个进程写,属于临界资源,多个进程竞争锁资源,使得并行变串行。
图6是图5中并行I/O在逻辑视图上的展示。
2.3 Lustre简单设置
1. 查看OST
1 | $ lfs df -h |
2. 查看stripe count和stripe size
1 | $ cd /lus/nid00008/user123 |
上例中, 默认stripe count是2,stripe size是1MiB。默认设置是在文件系统初始化时配置的。
3. 设置Stripe Count和Stripe Size
1 | $ cd /lus/nid00008/user123 |
上面的例子中将所有newdir中所有文件的stripe count设置为8,stripe size为1MiB,newdir下所有新创建的文件都适用这一设置。
注:还有其他方法能改变Lustre的stripe size,如MPI-IO hints
3. I/O 接口
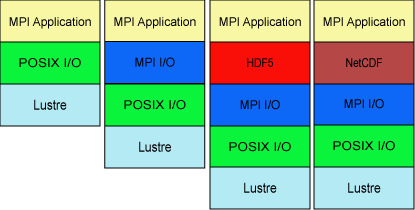
并行IO中通常有四种接口,POSIX I/O,MPI I/O,HDF5 I/O,NetCDF-4 I/O,如图7所示。MPI应用程序使用一种或者多种I/O接口。
3.1 POSIX I/O
POSIX I/O的文件由连续的字节组成。应用程序可直接使用POSIX I/O接口,或者使用C语言库函数间接调用POSIX I/O。基本的POSIX I/O函数如:read()将连续字节串从磁盘转移到内存,write()将连续字节串从内存转移到磁盘,readv()将磁盘中连续的字节串转换成内存中不连续的字节串,writev()将内存中不连续的字节串转换成磁盘中连续的字节串。
POSIX I/O提供最基本的I/O操作,但是却没有并行I/O的基因。如果要实现POSIX I/O并行,很多事情需要在应用程序中定义,如文件显式的offset。另外POSIX不支持collective操作,也就是说进程中的协作需要应用程序显式地定义。而且如果需要将复杂的数据结构写入到文件中,那必须将(内存中)非连续的块拆分成若干个连续的块,并分别调用POSIX接口写入到文件中。
如果使用POSIX接口的应用程序对I/O性能有较高要求,那么需要针对具体环境(如进程数、文件系统特性)修改应用程序,但是这样会导致程序的移植性差。
3.2 MPI I/O
MPI I/O提供两种类型的接口:Independent I/O 和Collective I/O.
Independent I/O中,每个进程独立地处理I/O, Independent I/O基本的操作是,MPI_File_read()和MPI_File_write()。 这两个函数与MPI的send和receive操作很类似。
1 | int MPI_File_write(MPI_File mpi_fh, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) |
Collective I/O 中所有进程以特定的顺序调用I/O。 基本的Collective操作: MPI_File_write_all()和MPI_File_read_all()。 与Independent I/O在语法上的差别就是多了一个all后缀。
1 | int MPI_File_write(MPI_File mpi_fh, void *buf, int count, MPI_Datatype datatype, MPI_Status *status) |
all后缀就意味着MPI通信域中所有拥有文件句柄的进程都都要执行write操作。
MPI I/O文件是一种有序的数据集合。你可以根据你的应用程序定义合适的数据类型。在自定义数据类型后,在函数MPI_File_set_view()使用。有了这样强大的操作,每个进程都可以定义自己的文件视图,这样做的好处就是你不用再去操心每次IO操作的指针偏移量了。任何读写共享文件的进程都通过MPI_File_set_view()去定义自己要读写的数据。一旦文件视图设置完成,MPI IO程序就自动帮你计算每个进程的指针偏移量。
无论是Independent I/O 还是Collective I/O,MPI 都能提供独立文件指针和显示使用文指针偏移量的函数,方便为不同编程范式提供灵活的编程方式。相比POSIX,MPI I/O提供更高级的数据抽象,你能够使用MPI I/O为并行应用程序定义更复杂的I/O访问模式,从而优化程序性能。
Independent I/O和POSIX I/O类似,但是也有不同点。
POSIX I/O只仅支持连续文件块的读写,Independent I/O支持衍生的数据类型,能够支持非连续的数据读写。
大多数并行程序都使用Collective I/O,因为Collective I/O能够高效处理多进程同时读写数据。
3.3 HDF5 I/O
HDF5是跨平台的I/O接口,对复杂的数据对象拥有的良好的兼容性,HDF5提供比MPI I/O更高级的数据抽象。
HDF5 I/O的基本操作是H5Dread()和 H5Dwrite()。
MPI I/O一次只能处理一个I/O操作,HDF5将多个I/O操作作为一个逻辑实体操作,因此比MPI I/O拥有更多的优化可能性,也可以为MPI I/O提供hints。
HDF5文件采用“自描述”模式,意味着文件包含描述数据类型的信息。“自描述”类型的文件是跨平台的。
3.4 NetCDF-4 I/O
与HDF5类似,NetCDF-4 也是跨平台的I/O接口,通过NetCDF-4接口你可以创建,访问,共享阵列型数据。NetCDF-4 提供比MPI I/O更高级的数据抽象. NetCDF-4 将数据视为相互联系的阵列集合。NetCDF-4 数据模型包括变量,维度,属性和用户自定义的数据类型。
NetCDF-4 文件同样是“自描述”。NetCDF-4提供的数据也可以被使用HDF5接口的应用程序访问。
4. I/O 策略
并行程序通常是一个或多个进程读写一个或多个文件,I/O模式有以下四种情况:
- 每个进程一个文件(FPP): 所有进程参与写。
- 一个共享文件: 一个进程参与写。
- 一个共享文件: 所有进程参与写。
- 一个共享文件: 部分进程参与写。
事实上没有一个一劳永逸的I/O策略,对不同的应用程序,不同的进程数,最优化的I/O策略总是不同的。
4.1 每个进程一个文件(FPP)——所有进程参与写
每个进程写一个文件,如图8所示,通常情况下由于多个OST可以支持多文件并行读写,这种策略显得简单有效。
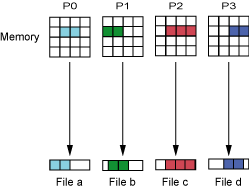
但是当大量文件同时打开或关闭时,所有文件的元数据都靠一个MDT处理,给MDT造成很大压力而性能下降,同时当进程与OST的比率较大时(多少比率)是,也会给OST带来很大压力,因此当应用程序规模较大时,不建议采用这种策略。
4.2 一个共享文件——一个进程参与写
该策略下,所有参加I/O的进程将写请求统一发送给一个进程,由这个进程一次写入到共享文件中。如图9所示P1-P3将写请求发送给P0,P0将P0-P3的数据一次写入到共享文件中。
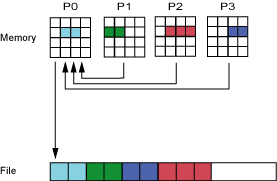
这种策略使用的是被称作聚合器(aggregator)的技术,使用某个进程作为聚合器,其他进程将数据发送给聚合器,聚合器进行整合并写入文件。
显而易见,这种策略不会给MDT带来任何压力,因为所有数据都已经提前被聚合,MDT只接受一次请求,但是该策略有不足之处,显然这种操作是串行的,写带宽就是一个进程写入时所能带来的带宽。
4.3 一个共享文件——所有进程参与写
如图10示所有进程同时写一个共享文件。该策略需要应用程序计算每个进程的文件指针偏移量,以防止应用程序之间的数据篡写。由于所有进程都在同时写,所以I/O过程是并行的。这种方法有一个缺点就是文件块大于stripe size时,每个OST都要同时服务多个进程,会导致磁盘的频繁寻道参考文献ICS’10。
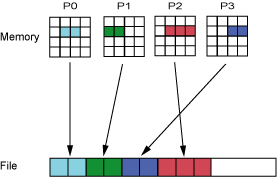
4.4 一个共享文件——部分进程参与写
如图11所示,通过聚合器,数据被聚合成多个子集,同时写入一个共享文件。由于写次数减少,MDT的瓶颈问题也得到缓解。这种策略是4.1和4.2的平衡,保证并行性的同时减少I/O竞争。所以寻找最佳性能平衡点是采用这种I/O策略的难点,因为平衡点可能会随着数据集的大小或者I/O系统特性的不同而变化。这种优化方法的实现有著名的’two phase io‘,被集成在ROMIO中。